Before I joined Bronto, two things had to be true
Severin Neumann
Head of Community

I’ve been in the observability space long enough, through OpenTelemetry, by seeing and doing dozens of vendor pitches and enough “AI-powered” demos to last a lifetime. So I have a clear idea about what a company needs to be successful in this area, and what would actually make me passionate about working for one:
- A data layer for all telemetry that is orders of magnitude faster and more efficient than others.
- The API has to be the kind you can build on without fighting.
So when I was asked to join Bronto as Head of Community, and I felt that the people are the ones I want to work with, I had one last thing to do: confirm that both my requirements are met by the product. I’ll come back to what I built, but first, why those two things in the first place.
Orders of magnitude, not percentages
Many observability solutions don’t build their own storage. They take a best-in-class open source database and build their solution on top of it. This is a recipe that works, as many of them have proven, and it is the smart thing to do if building such an engine is not your area of expertise.
But it’s also a way of routing around the hardest problem in this space instead of solving it. The observability cost problem isn’t new. We’ve been complaining about it for well over a decade. And in all that time the industry’s answer has mostly been compression, sampling, tiering, drop filters. Every one of them is a percentage play. I said before that a 50% data reduction won’t cut it: we need innovation in the data layer itself, where costs come down by 90% or 99%, while querying gets faster and retention gets longer. The reason nobody had done that isn’t that nobody wanted it. It’s that building a telemetry storage engine from scratch is genuinely hard, and it’s a completely different discipline from building a great observability UX. So almost everyone, reasonably, chose not to.
Yet, the pressure is only getting worse. The amount of data teams ingest is growing exponentially, so every 30% or 50% you claw back gets eaten up in a quarter. The rise of agents accelerates it twice over: they generate more data, and they’re increasingly the main consumers of it. This means queries have to be fast and retention has to be long, so an agent can test hypotheses against real history and actually get to a root cause.
This is the bet Bronto made: they built BrontoDB, a self-tuning columnar engine that organizes itself around your data: sparse keys, unstructured logs, whatever you throw at it, instead of the other way around. A database that can give you >100X more data than you are used to while not compromising on speed. So truly the orders of magnitude that is needed heading into an AI age. Furthermore a database with a year of hot retention by default, and no cold storage to fall through to. These are not features you bolt on! This is a multi-year commitment to solving the thing everyone else decided to build around. Which is why I didn’t want to take it on faith. A claim this big is exactly the kind you have to go and test yourself.
The API is becoming the front door
For the longest time, monitoring and observability platforms differentiated by their UIs: which one is easier to use for humans, leads them quicker to the root cause, and is better able to put things into context. While this is still essential, a lot of the ways how observability data should be presented has been figured out, and solutions share a common set of views and display widgets across the board.
Nowadays the attention is shifting to APIs, as they are the main interface for agents to interact with software. I say that this shift is happening finally, because they have been neglected for the longest time, which was painful for humans already! A lot of solutions did not provide APIs, or have them bolted on carelessly later, or have never cared to document them.
This hurts any kind of machine-based integrations: code reviews, automated deployments, automated remediation and agent-based interactions. So gladly this pain now got everyone’s attention, and while APIs and their documentation are built out for agentic workflows, they help in many other ways too. Bronto bet on this early. Same capabilities exposed through REST and MCP, and documentation written for someone who actually wants to build, not just survive.
Does Bronto have both?
Of course there are many other things an observability platform should do, but those two are key ingredients to be competitive against the incumbents in the market. So I checked if Bronto has them both. The first check is going into the product and sending some queries to retrieve large data sets, and yes, it’s that fast. But a better test is building things that put those two criteria to the test:
- A command line interface (CLI) to interact with the Bronto API, all vibe coded.
- A service map view, which is a query intensive view, built on top of BrontoVibe.
Let me take them one at a time.
Test 1: a CLI
While API and MCP, the open protocol agents use to talk to your services, are all you need to get yourself and the agents started to interact with software, the CLI is a great convenience wrapper, that makes it easy for humans and agents alike to quickly test out things, explore things, and reduce long curl commands into one-line statements in your automations. More important: building a CLI makes direct use of the documentation available for the API: the coding agent pulls in the docs and specs, creates commands and subcommands based on them, and puts them to test.
That’s what I did. I spun up my favourite coding agent and said: “build a CLI for Bronto”! A few minutes later it handed me a Python-based solution. I typed bronto traces services, hit enter, and watched a list of services come back. The agent had never seen this API before, only the docs. From there I drilled into a trace by ID, an ASCII waterfall rendered in the terminal. First try (asciinema recording).

This is far from perfect and also not the CLI I want for Bronto eventually (not using Python for it is one of many things I would change in a second round), but this experiment checks all the boxes: API is great, docs for the API are great, queries are fast!
You can check out the CLI here: https://github.com/svrnm/bronto-cli
Test 2: a service map
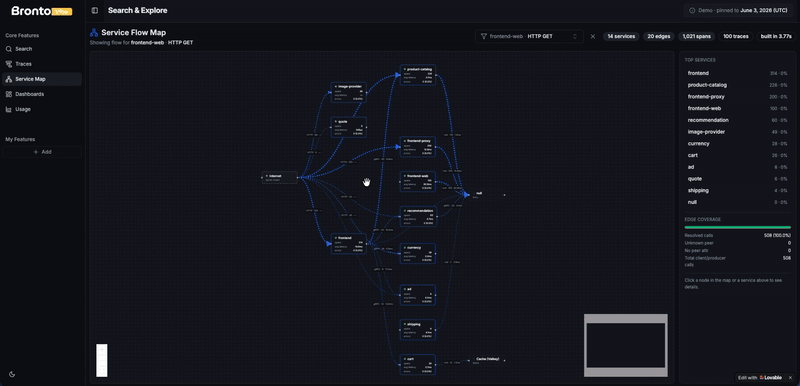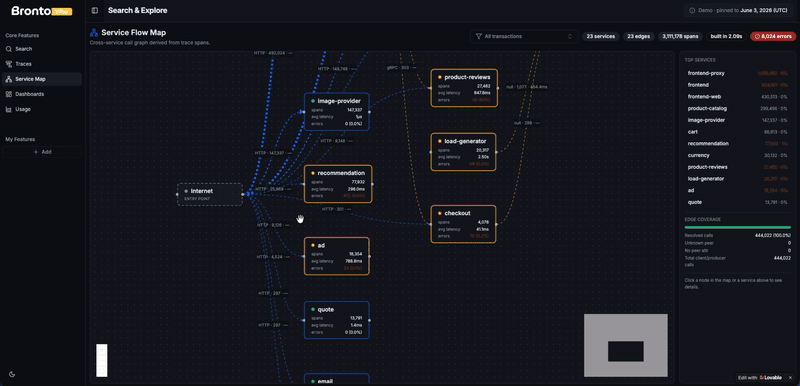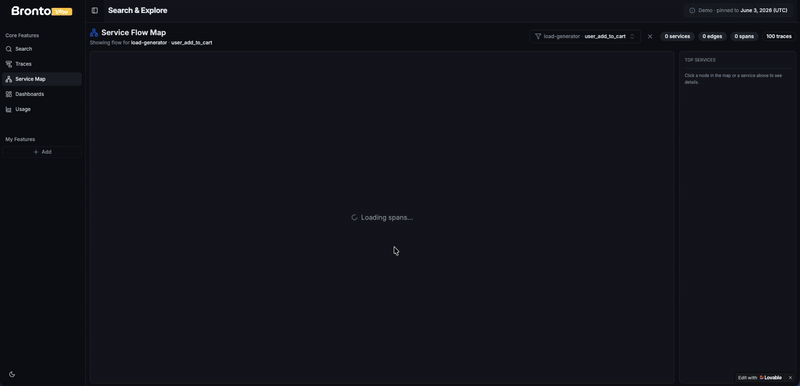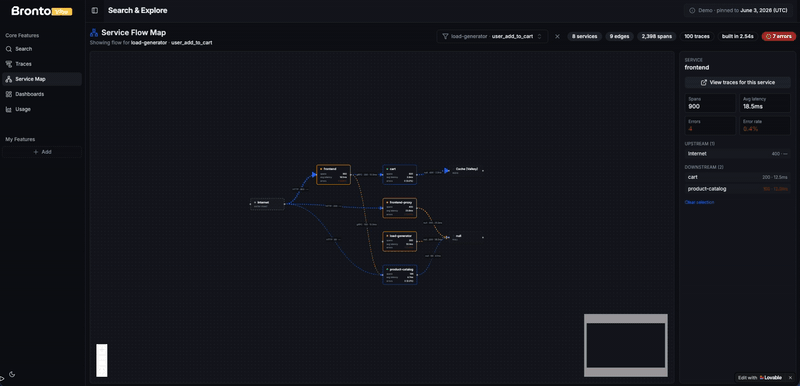
When I entered the observability (or back then application performance management) space a decade ago, service maps or data flow maps were the view that hooked me. Seeing your code, your services, your databases and 3rd party components interact in a single view felt, and still feels, like magic. It gives your architecture a shape, and it gives a human a way to quickly validate that all the things are there that make up the application (and that there are no things that shouldn’t be there, like the staging instead of production database). These maps, if built solely from traces and not optimized at all, can also be fairly intense on your telemetry database, so another great candidate for testing out Bronto.
What made this task super easy was BrontoVibe, built exactly for bringing your own UI to Bronto. So I clicked the remix button, signed up for Lovable, and sent another prompt: “build a service map of the Bronto trace data”.
It took the agent a few minutes, and it also required some steering and corrections, but eventually this experiment checked the boxes too: the API was once again easy to consume for the agent to build what I wanted, and the service map, while not yet 100% perfect, was created from millions of traces in seconds. And the part that impressed me most: I never bothered to optimize or aggregate the data. When something did eventually slow down, it was the browser pulling all of it, not Bronto serving it.
Going forward, service maps might be a thing of the past, and having them in your modern observability solution might not be a necessity, but they are candy for your eyes. Here’s the one I built, if you want to remix it.
Build with us

The people of Bronto are great, the product checks all my requirements, and their mascot is a dinosaur! But the thing that tipped it wasn’t any single checkbox: it was that this team chose to go straight at the problem everyone else has spent a decade building around, and clearly has the chops to pull it off. That’s the kind of bet I want to be part of. So here I am as Head of Community. I chose community over a DevRel-style role because the work I actually love is the peer-to-peer kind. A community that’s not only using Bronto, but more importantly building with Bronto. CLIs, custom UIs, agents, integrations, weird experiments, side projects, automations, production tools, things nobody at Bronto thought of yet. Rooted in the OpenTelemetry and cloud native communities I already live in, pointed at something new. I’ll be building myself, but I am more excited to see what you build! If you’ve been waiting for permission, this is it. Come build with us.