A framework for CDN logging total cost of ownership

A logging platform's true cost at CDN volume is the product of several compounding charges: ingestion, storage, query, rehydration, and operational overhead. Here's how to calculate the real number.
What you'll learn in this guide
- How to calculate what you're actually spending on CDN logging — including the hidden costs of cold storage operations, pipeline maintenance, and the engineering time consumed by a fragmented stack
- Why per-GB pricing models systematically undercount total cost of ownership — and what the bill looks like when you account for storage, query, rehydration, and coverage compromises
- How to build the business case for a migration: the cost comparison framework, what to measure, and the retention and coverage ROI arguments that resonate with engineering leadership
- What migration actually involves — why most teams are live on Bronto within days, not months
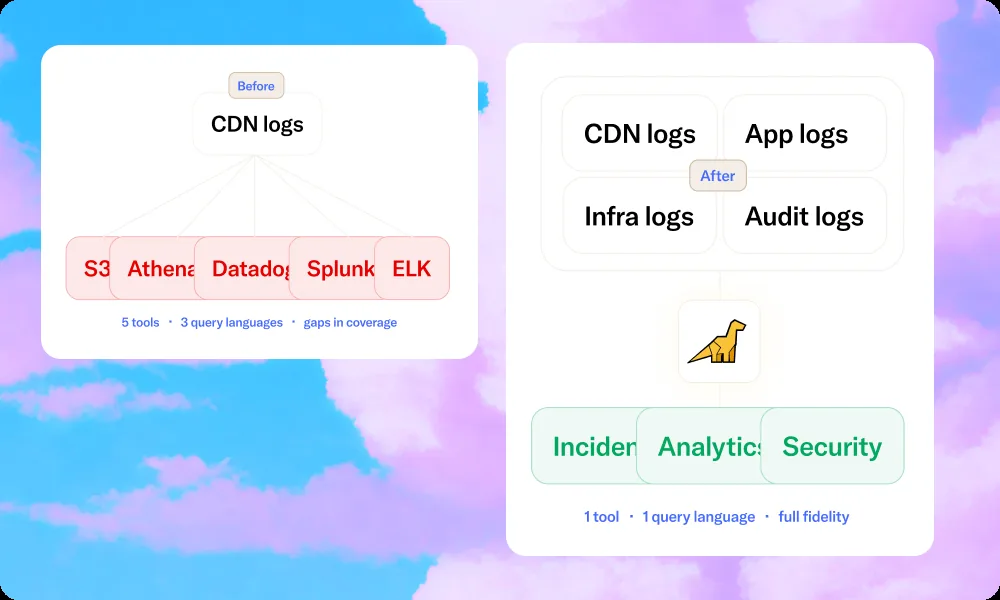
When engineering leaders compare CDN logging platforms, the comparison usually starts with the ingestion rate — cost per GB received. It's the number vendors lead with, it's the simplest to compare, but it's misleading.
A logging platform's true cost at CDN volume is the product of several compounding charges: ingestion, storage, query or compute, rehydration, and the operational overhead of the engineers who maintain it. Ingestion is just one input into that calculation.
The result is that most organisations are significantly overpaying for logging, because the full cost structure only becomes visible at scale, by which point switching feels risky and disruptive. This guide is about making that calculation explicit, so the decision can be made on accurate numbers rather than a vendor's introductory pricing page.
How per-GB pricing works at CDN scale
Traditional logging platforms were designed before the separation of compute and storage was commercially viable. They provision clusters that are running and billing whether you're querying or not, maintain expensive inverted indexes to deliver query speed, and recover those infrastructure costs through per-GB pricing across every stage of the data lifecycle.
At modest log volumes — application logs for a mid-sized service — this model is manageable. CDN logs are a different order of magnitude. A busy Fastly or Cloudflare deployment generates tens of thousands of log lines per second. At that volume, per-GB pricing at every lifecycle stage compounds quickly.
The per-GB cost multiplier: what you're actually paying
On a typical GB-in + GB-stored + GB-queried platform, a single GB of CDN log data incurs cost at every stage of its lifecycle:
1. Ingestion: charged per GB received. For a busy CDN deployment, this is the first bill that appears on the invoice and the first one that triggers a sampling decision.
2. Storage: charged per GB per day retained. With inverted index overhead, the effective storage cost is typically 1.5–2x the raw data size. Extended retention multiplies this linearly.
3. Query: charged per GB scanned on some platforms; charged via cluster resources on others. Either way, long-range historical queries are the most expensive — and the most analytically valuable.
4. Rehydration: moving data from cold storage to a queryable state incurs both a per-GB transfer fee and engineering time.
By the time you've paid for ingestion, storage with index overhead, queries, and occasional rehydration, the effective cost per GB is typically a multiple of the headline ingestion rate.
The hidden costs: what doesn't appear on the invoice
Indirect costs are harder to quantify but often comparable in magnitude to what appears on your bill.
- Operational overhead: Engineering time spent on logging infrastructure maintenance
- MTTR tax: Increased MTTR during incidents caused by slow queries, tool-switching, or missing data
- Coverage opportunity cost: The analysis you can't do because retention windows are too short or data has been sampled
- Schema maintenance: Recurring engineering effort when CDN providers update their log formats and parsers break
- Rehydration overhead: The time spent rehydrating cold storage archives every time you require historical data
Building the business case for migration
| Cost component | Traditional (Datadog/Splunk class) | DIY S3 + Athena | Bronto |
|---|---|---|---|
| Ingestion cost | High — per-GB rate; first trigger for sampling decisions | Low — S3 PUT costs minimal | Ingestion-only pricing; no multiplier for storage or query |
| Storage cost (with index overhead) | High — inverted index typically doubles raw data footprint | Low — raw S3 storage; but no index | Object storage with Bloom filters; fraction of inverted index overhead |
| Query / compute cost | Included in platform fee — but cluster provisioned 24/7 | Per-scan Athena cost | Serverless; compute scales on demand; not metered separately |
| Rehydration cost | Manual; time + per-GB transfer fees | Standard rehydration from Glacier; hours of wait time | No rehydration — all 12 months always hot |
| Retention ceiling before cost inflects | 7–30 days practical; >90 days requires significant budget increase | Unlimited storage; query cost grows with lookback | 12 months default; no cost increase for longer lookback |
| Pipeline / schema maintenance overhead | Low ops; schema changes require parser updates | Medium — Glue crawlers, partition management | Schema-agnostic; auto-parsed |
| Engineering time cost | Low direct ops; high indirect cost | Medium-high — partition management + query iteration | Minimal — no cluster ops, no rehydration jobs |
| Typical total cost vs. Datadog at CDN volume | Baseline | 30–50% lower on storage; similar on total ops cost | 50–90% lower than Datadog-class |
The key insight: DIY object storage appears cheap in a direct cost model because storage is cheap. The cost that doesn't appear is query latency during incidents, Athena scan costs on long historical ranges, and the engineering time required to manage partition structures, Glue crawlers, and schema evolution.
The cost reduction argument
The most direct comparison is current annual spend on CDN logging (direct platform costs + estimated engineering overhead) against projected Bronto cost at the same volume. Bronto's ingestion-only pricing can reduce costs at CDN volume by as much as 90% while offering 10x longer retention, versus traditional platforms like Datadog.
The coverage and retention argument
Retention has compounding value. The categories of analysis that require 12+ months of CDN log data include:
- Year-over-year performance benchmarking: comparing Black Friday or peak product launch traffic against the equivalent period the previous year
- Security forensics with full audit depth: investigating attack campaigns or compliance incidents that started weeks or months before they were detected
- Capacity planning grounded in historical patterns: real seasonal demand curves from CDN telemetry rather than estimates
- Customer SLA reporting with longitudinal depth: for platforms with per-customer identifiers, multi-month latency and error rate analysis becomes a standard query
The migration simplicity argument
The most common objection to a CDN logging migration is implementation risk. Bronto is auto-parsed and requires no schema config for standard formats before ingestion starts. It integrates with the same pipeline tooling most teams are already running. And it supports parallel operation.
Migration path by pipeline type: what it actually involves
| Existing pipeline | What changes | Effort | Parallel run possible? |
|---|---|---|---|
| Fluent Bit | Add Bronto HTTP output stanza to fluent-bit.conf | < 1 hour | Yes |
| Vector | Add bronto_http sink to vector.toml | < 1 hour | Yes |
| OTel Collector | Add OTLP HTTP exporter pointing to Bronto endpoint | < 2 hours | Yes |
| Fastly log streaming | Add HTTPS logging endpoint in Fastly service config | < 1 hour | Yes |
| Cloudflare Logpush | Add new Logpush job targeting Bronto HTTP endpoint | < 2 hours | Yes |
| Akamai DataStream 2 | Configure DataStream 2 delivery connector to Bronto | < 2 hours | Yes |
| Direct S3 delivery | Configure S3 event notification to forward to Bronto | 2–4 hours | Yes |
In every case, the integration is additive. You don't need to remove or modify your existing pipeline before validating Bronto.
Nasuni: from 90-day retention and 15-minute queries to 12-month history at sub-second speed
Nasuni runs a distributed enterprise storage platform with tens of thousands of appliances deployed globally. Before Bronto, Nasuni was on 90-day retention. Typical queries took 15 minutes. Rehydration from cold storage was a regular operational requirement.
After migrating to Bronto:
- Retention extended to 12 months, enabling annual trend analysis and capacity planning
- Query times reduced from 15 minutes to sub-second — a 95%+ reduction in MTTR for log-dependent investigation
- Eliminated expensive JSON conversion requirements
- Correlation analysis across tens of thousands of appliances became practical
- Engineering teams shifted from avoiding logs to actively using them
"Tasks that used to take 15 minutes are now almost instant. With a year's worth of data retention instead of just 90 days, I can now identify annual trends and patterns I couldn't see before."
Elliott, Senior Engineering Manager, SaaS Services, Nasuni
Evaluation checklist: questions to ask any CDN logging vendor
On pricing structure
- What is charged at ingestion? At storage? At query time? Are these metered separately or bundled?
- How does your index overhead affect effective storage cost?
- Is there a per-GB charge for rehydration from archive or cold tiers?
- What happens to cost when we double our CDN log volume?
On retention and fidelity
- What is the maximum retention period available without moving to archive or cold storage?
- Is data from 6 months ago queryable at the same latency as data from yesterday?
- Does full-fidelity ingestion at our CDN volume produce a bill we can sustain?
On migration and operational overhead
- Can we run your platform in parallel with our existing stack while validating?
- What changes are required to our existing Fluent Bit / Vector / OTel Collector configuration?
- What ongoing operational tasks does running your platform require from our team?
Start a Free Trial of Bronto
Try Bronto for free for 14 days and see how it handles your logs at any volume, with no query fees and sub-second search.
Start a Free Trial of Bronto →