Centralizing CDN logs: a guide to high-volume log management

What centralised CDN logging actually requires when your providers each generate tens of thousands of log lines per second, and what it takes to keep that data queryable.
What you'll learn in this guide
- What centralised CDN logging actually means, why per-provider silos make analysis unreliable, and where most current setups fall short
- Guidance on the most important requirements of a centralised CDN logging layer and an honest assessment of whether typical current setups satisfy them
- The implications of peak traffic events and what designing for peak rather than average load actually involves
- What a modern unified CDN logging layer looks like in practice, with real performance numbers from production deployments
You have CDN logs, but do you have CDN visibility?
If you're running Fastly in front of your API tier, with Cloudflare handling your web properties, and possibly Akamai for media or large-file delivery, each of those providers is generating a continuous stream of high-value telemetry: every cache hit and miss, every origin pull, every edge error, every millisecond of latency at the PoP nearest to your users.
That data collectively tells the full story of what your users are experiencing at the edge. In practice, most engineering teams only see fragments of it because centralising CDN logs across multiple providers, at the volumes modern CDNs produce, against a retention window long enough to be analytically useful, turns out to be extortionately expensive.
The typical result is a patchwork: per-provider dashboards that can't be queried together, an S3 bucket that's theoretically comprehensive but prohibitively expensive to query at CDN volume, and a roll-your-own ingestion layer stitched together to keep costs down, one that works fine until a provider updates their log format or traffic spikes and the whole thing needs attention at the worst possible moment.
This guide is a ground-up primer on what centralised CDN logging actually requires, not as a features checklist, but as a set of architectural and operational requirements that determine whether your logging holds up when it matters most.
The three failure modes of traditional CDN logging
Volume economics break at CDN scale
CDN logs are typically high-cardinality and high-volume by nature. A mid-size e-commerce platform pushing 50TB of CDN log data per month isn't unusual. At traditional volume-based pricing, $2–5 per GB ingestion plus storage costs: that's a six-figure monthly bill before you've written a single query.
The inevitable response is sampling, filtering, or dropping fields. You ingest 10% of requests. You drop the headers. You exclude lower-priority regions entirely. Every one of those decisions is a blind spot you'll wish you hadn't created the next time an incident hits a region you excluded. You've engineered visibility gaps to control the bill.
Query performance collapses when it matters most
Peak traffic events: product launches, sporting events, Black Friday — are exactly when you need your logging to be fast and reliable. They're also when your logging is most likely to fall over.
This isn't coincidental. Most logging architectures are optimized for average load. When traffic spikes 10x and log volume follows, query performance degrades non-linearly. A query that runs in 45 seconds at normal load might take 30+ minutes under peak ingestion. The on-call engineer ends up flying blind at exactly the wrong moment.
Designing for peak traffic, rather than average traffic, requires a fundamentally different architecture.
Retention windows make historical analysis impossible
CDN log data has a long tail of value. You need sub-second access to debug an active incident, but you also need 12 months of data to:
- Compare this Black Friday to last Black Friday
- Identify seasonal cache performance patterns
- Run year-over-year latency trends for SLA reviews
- Support security forensics investigations that surface weeks after an event
What centralized CDN logging requires
Bringing CDN logs from multiple providers into a unified, queryable layer sounds straightforward. In practice, it requires solving several distinct problems simultaneously.
| Requirement | Why | Reality |
|---|---|---|
| Multi-provider ingestion | Different schemas across CDNs. Standardization enables consistent queries. | Siloed pipelines or fragile ETL. Cross-CDN analysis becomes engineering work. |
| High-throughput ingest | Traffic spikes require stable ingestion or dashboards break. | Pipelines sized for averages. Spikes cause drops and lag. |
| Sub-second query | Fast feedback is required for incident response. | Performance degrades under load. Queries take minutes. |
| 12+ month retention | Historical data must be instantly accessible. | Cold storage delays make data unusable in real time. |
| Cost-efficient at scale | Full-fidelity logs are required for accuracy. | Pricing forces sampling and reduced retention. |
| PII handling at edge | Sensitive data must be masked before storage. | Manual pipelines break and create compliance gaps. |
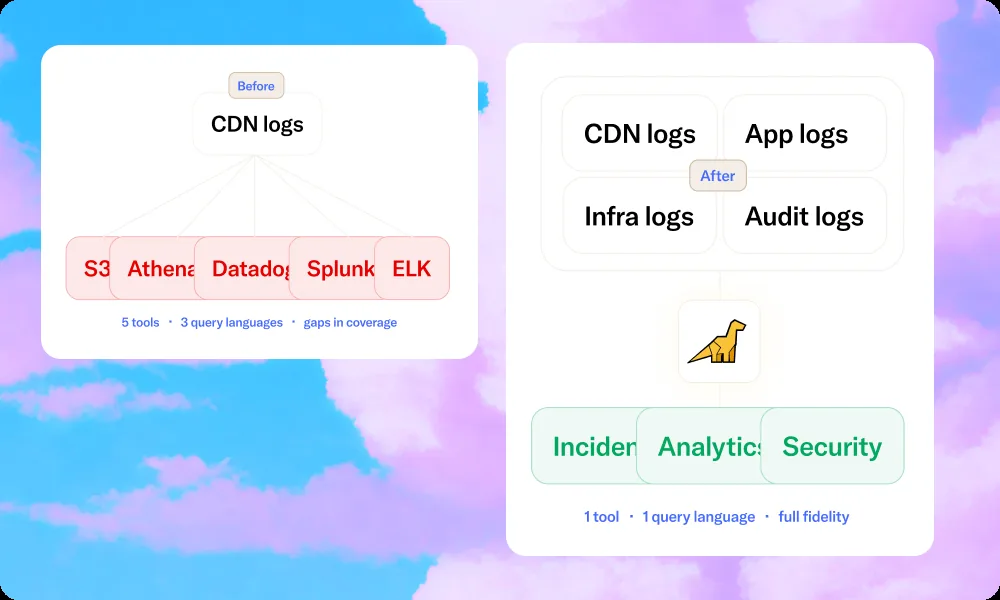
Most organizations end up building a patchwork to cover these requirements: a streaming pipeline feeding a primary logging tool, an S3 archive for longer retention, a separate analytics system for historical queries, and custom glue code to tie it together. The result is five systems that each do one thing adequately, and a maintenance burden that follows your team into every on-call rotation.
The architecture that works at CDN scale
The core problem with centralizing CDN logs is that the incumbent platforms were priced and architected before CDN-scale volumes became the norm. Their business models assume you'll control costs by limiting what you ingest and how long you keep it. But for CDN volumes, that's not a smart operational decision.
Legacy vendors charge per GB at ingestion, per GB at storage, and per GB at query time. That pricing model worked when logs were a fraction of today's volumes. At 50TB/month of CDN data, it produces bills that force exactly the compromises you're trying to avoid: sample down, shorten retention, drop fields.
Rolling your own doesn't fix the economics, it trades the vendor bill for an engineering and operational burden. Pipelines need maintenance. Clusters need tuning. On-call engineers end up managing logging infrastructure instead of the systems it's supposed to monitor.
What CDN-scale logging actually requires is an architecture that separates compute from storage, so you're not paying for query capacity you're not using; keeps costs flat as volume grows rather than scaling linearly with it; and treats 12-month retention as a default, not a premium tier.
How Bronto solves this
Sub-second search at terabyte scale
Bloom filter indexing delivers queries in under a second across terabytes — a consistent operational baseline, not a best-case benchmark. Contentstack queries 1TB in ~25ms; 100TB in ~2.5 seconds, even during peak traffic.
Native Fastly and Cloudflare integrations
Bronto connects directly to your CDN providers without custom pipeline work. Log streaming is configured in minutes, not days.
12-month hot retention, no rehydration
All data is instantly searchable regardless of age. Year-over-year comparisons become routine: last Black Friday's data is as fast to query as yesterday's.
50% cost reduction with broader coverage
ContentStack cut their logging bill in half while expanding to both Fastly and Cloudflare. Compared to legacy vendors like Datadog, Bronto can reduce costs by up to 90% with 10x longer retention.
Auto-parsing with no GROK configuration
CDN log formats vary by provider, version, and configuration. Bronto's AI parser handles format detection and normalization automatically — structured and searchable from first ingestion.
Usage Explorer for cost visibility
See exactly which log sources are driving costs, which teams are running which queries, and where the optimization opportunities actually are.
ContentStack went from 2 weeks of retention to 12 months. They can now analyze API latency trends over time, identify seasonal patterns, and build business-level reports from their log data — use cases that simply weren't possible before.
Comparison: Traditional CDN logging vs. Bronto
| Capability | Traditional | Bronto |
|---|---|---|
| Query speed (terabyte scale) | 15–30+ minutes or timeout | Sub-second to seconds |
| Retention | 14–30 days, cost-limited | 12 months, instantly searchable |
| Multi-CDN normalization | Custom pipelines required | Native integrations across providers |
| Peak traffic handling | Degrades under load | Serverless search, no performance cliff |
| Cost trajectory | Linear with volume | Decoupled compute and storage |
| Parser configuration | Manual GROK or regex | AI-powered, zero config |
| PII handling | Manual implementation | Automatic detection and masking |
| Year-over-year analysis | Not possible | Standard use case |
Evaluating your current setup: a six-question audit
Use these questions to assess whether your existing CDN logging setup meets the requirements above. If you can't answer yes to all of them, you have a gap worth addressing before your next peak traffic event.
- Can you run a single query across Fastly and Cloudflare logs simultaneously, with normalised field names, without writing custom SQL or transforming the data first?
- If your CDN traffic spikes 10x right now, does your logging ingest absorb the burst without dropping events or degrading query latency on your dashboards?
- Can you query log data from 6 months ago at the same speed as log data from 6 hours ago, without triggering a restore job?
- Could you answer "how did this Black Friday's cache performance compare to last year's" with a single query against live data?
- Are you ingesting 100% of CDN log events at full field fidelity, or have you made sampling or field-dropping decisions to stay within budget?
- Is PII in your CDN logs, client IP addresses, sensitive URL parameters: automatically masked before storage, with no manual pipeline step required to handle new fields?
If you answered no to two or more of these, your CDN logging setup has architectural gaps that will surface as operational problems. The good news: for most teams, closing those gaps doesn't require a large migration project, it's just a single pipeline change.
Start a Free Trial of Bronto
Try Bronto for free for 14 days and see how it handles your logs at any volume, with no query fees and sub-second search.
Start a Free Trial of Bronto →More articles

CDN log analytics: a guide to full-fidelity Fastly and Cloudflare logging
The CDN observability consolidation guide: replace 5–8 tools with one logging layer

