CDN observability at edge scale: why full-fidelity logging requires a different architecture

Why traditional observability platforms struggle at CDN log volumes — and why the problem is architectural, not just a pricing issue.
What you'll learn in this guide
- How Bloom filter indexing, decoupled compute/storage, and serverless query execution work together to deliver sub-second search at terabyte scale
- Why traditional observability platforms struggle at CDN log volumes — and why the problem is architectural, not just a pricing issue
- What the architecture tradeoffs look like between inverted indexes, DIY S3/Athena, and purpose-built logging — on fidelity, retention, query latency, and operational cost
- What changes operationally when you can keep 12 months of unsampled CDN logs instantly queryable
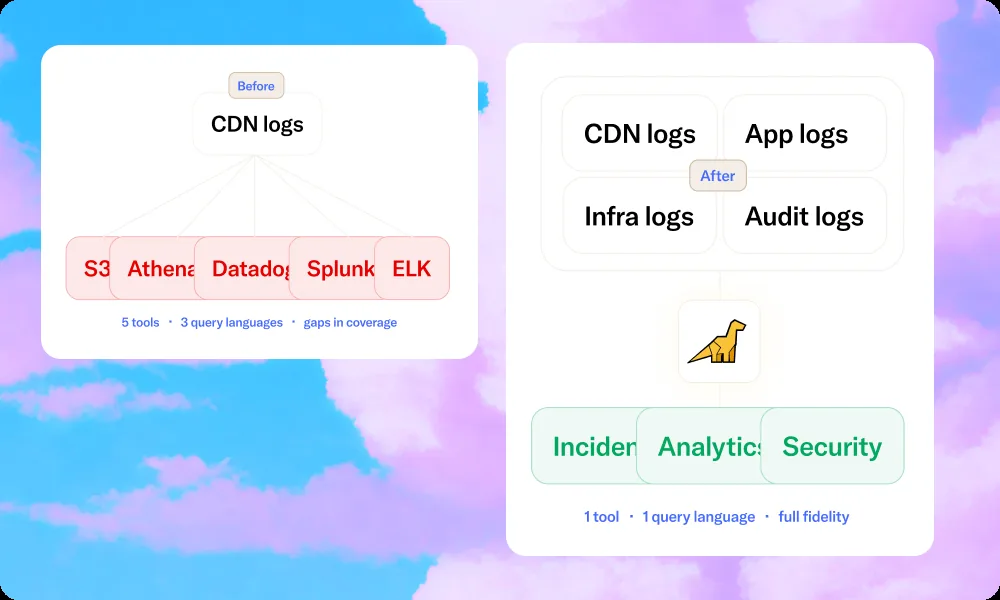
What happens when your CDN scales but your logging doesn't
CDN logs contain the ground truth of your users' experience: which requests hit cache, which did not, where latency spiked, which PoPs are underperforming, and what the ASN composition of your traffic tells you about automated bot activity.
The problem is volume. A busy Fastly or Cloudflare deployment at peak produces tens of thousands of log lines per second. Traditional observability platforms were built for application log volumes — orders of magnitude lower, with much more predictable cardinality.
When you route CDN telemetry through a platform priced on GB ingested, GB stored, and GB queried, the economics break fast. The rational response is to sample down, shorten retention, pre-aggregate to summaries, and drop the raw rows. By the time a P0 hits at 3am, you're trying to reconstruct what happened from a 10% sample with a 14-day retention window.
Why legacy platforms can't handle CDN log volumes
Inverted indexes struggle at CDN scale
Most traditional logging platforms were built on inverted indexes that index every token in every event. CDN logs contain high-cardinality fields — URL paths, user agents, ASNs, session IDs — that cause those indexes to balloon and degrade. Index maintenance becomes a full-time operational problem.
Tiered storage falls short for investigation
Many platforms respond to CDN volume costs with hot/cold tiering. It sounds reasonable until you actually need to investigate something. Tracing an attack pattern that started six weeks ago means waiting for a restore job or working from incomplete summary data.
DIY object storage breaks at query time
S3 storage is cheap, and the appeal of building your own pipeline is real. The problem surfaces at query time. Without an indexing layer, every query scans partitions — fine for a weekly report, painful for active incident triage.
Architecture options compared
| Approach | Query latency | Retention | Operational cost | Full fidelity? |
|---|---|---|---|---|
| Traditional observability (Datadog, Splunk etc) | Fast in hot window; degrades sharply beyond 7–14 days | 7–30 days practical at CDN volume; cost forces sampling | Low ops overhead; high per-GB cost | No — sampling is the economic response |
| CDN vendor native analytics | Fast on pre-aggregated data only | 7–30 days | Zero pipeline work; limited analytical depth | No — pre-aggregated, no per-request rows |
| DIY S3 + Athena | Minutes on partitioned scans; unusable during active incidents | Unlimited; storage is cheap | Medium — Glue/crawler infra, schema evolution overhead | Yes — but no indexing layer means scan-heavy queries |
| Self-managed cluster (ClickHouse, Elastic) | Fast when tuned; degrades without index maintenance | Tied to cluster capacity; you own the cost | High — shard management, capacity ops, upgrades | Yes — if you have the engineering to maintain it |
| Bronto | Sub-second on terabytes; seconds on petabytes via Bloom filter indexing + serverless execution | 12 months hot by default; no rehydration | Low — one config change to existing pipeline; SaaS managed | Yes — ingestion-only pricing; no sampling required |
How Bronto handles CDN log volumes
Bronto's founding team pioneered bloom filter indexing for log search at Logentries (acquired by Rapid7) and has been building logging platforms for over two decades. This is their fourth. Bronto was built from scratch specifically for high-volume, high-cardinality log data.
Bloom filter indexing instead of inverted indexes
A Bloom filter is a probabilistic data structure that answers one question: does this data block definitely not contain what you're looking for? If the answer is yes — the block is probably empty for your query — the execution engine skips it entirely. Compared to inverted indexes, Bloom filters are orders of magnitude smaller.
The result: sub-second queries on terabytes of CDN log data. Seconds on petabytes. For rare event lookups — a specific IP address appearing twice in millions of log events, or a specific error code on a specific endpoint — Bloom filters are especially effective because they immediately eliminate the vast majority of data blocks from the scan.
Decoupled compute and storage
Legacy platforms couple storage and compute — your data lives in hot clusters that are running and billing whether you're querying or not. When traffic spikes and log volume increases, you scale the cluster, which scales the cost. Bronto's architecture separates them. CDN logs live in cost-effective object storage. When you run a search, a serverless execution layer launches and parallelises the query across the relevant data partitions — as many parallel functions as the query requires. When the query completes, those resources are released.
The practical implication: a query over 10TB of edge data performs at similar latency to a query over 10GB, because the execution layer scales horizontally on demand.
Schema-agnostic ingestion
CDN log formats change. Providers add new WAF event fields, change how they report cache status, update header names. Bronto ingests your logs exactly as they arrive — no parsers required for standard CDN log formats. New fields are automatically available for search. You point your stream via S3, Kinesis, or HTTP and start querying.
Ingestion-only pricing
Platforms that charge on GB ingested + GB stored + GB queried create a compounding cost structure that makes full-fidelity CDN logging financially unworkable. Bronto charges on ingestion only. Storage and search are not separately metered. 12 months of hot retention is the default tier, not an add-on.
What changes when your CDN logs are fully retained and instantly queryable
Incident response without guessing
Identifying whether a latency spike is a regional ISP issue, a misconfigured cache rule, or origin degradation takes seconds — not 20 minutes of waiting for queries to return on a partial sample.
Year-over-year capacity planning
Actual PoP-level request distribution and bandwidth curves from the equivalent period last year aren't estimates — they're based on real, full-fidelity data.
Cost predictability that doesn't punish growth
Ingestion-only pricing means traffic spikes don't produce surprise overage bills. Bronto customers at CDN volume have seen up to 90% cost reduction compared to Datadog-class pricing.
Operational simplicity
No schema migrations when your CDN provider changes their log format. If you're already running Fluent Bit, Vector, or an OTel Collector, Bronto is an output stanza — one config change, no pipeline rework.
Start a Free Trial of Bronto
Try Bronto for free for 14 days and see how it handles your logs at any volume, with no query fees and sub-second search.
Start a Free Trial of Bronto →