Querying CDN logs with AI: what you should expect from your logging platform
An LLM that generates perfect SQL is still useless if that SQL takes 30 minutes to return. The bottleneck isn't the AI layer — it's the storage and query engine underneath it.
What you'll learn in this guide
- Why natural language querying of CDN logs is harder than it looks — and what actually makes it work
- The architecture trade-offs between query layers built on top of your storage vs. purpose-built platforms
- How full-fidelity retention changes what AI can actually tell you about your CDN traffic
- What Bronto's MCP Server and AI Dashboard Builder mean for your incident response workflow
It's 2 AM. An incident is open. Your CDN is reporting elevated error rates across three regions, and your on-call SRE is staring at a query that's been running for 25 minutes. When it finally returns they'll need to figure out whether the issue is a cache configuration drift, an origin timeout, a traffic spike hitting a cold edge node, or something else entirely. They're doing this half-asleep, under pressure, with a logging tool that wasn't designed for this moment.
The frustration isn't new. What is new is the expectation that AI can fix it — that you can just ask your logs a question in plain English and get a useful answer. That expectation is reasonable. But the way most teams are trying to get there isn't.
A growing number of teams are building custom AI query layers on top of their existing logging infrastructure: LLM-powered wrappers that translate natural language into SQL or query DSL, then fire those queries at whatever database sits underneath. The idea is sound. The execution hits a wall fast.
An LLM that generates perfect SQL is still useless if that SQL takes 30 minutes to return or times out entirely. The bottleneck isn't the AI layer. It's the storage and query engine underneath it.
This matters most for CDN logs, which are high-volume by nature. A global CDN can generate hundreds of gigabytes to multiple terabytes of log data per day. Getting an LLM to generate the right SQL is an interesting engineering problem. But if the underlying data is 2 weeks old, sampled at 10%, and the query times out under load the AI layer can't compensate.
What actually makes AI-native log querying work
There are a few things that separate a genuinely useful AI querying experience from a demo that breaks in production:
Sub-second query performance
If an AI agent waits minutes for results, the interaction model breaks down. Natural language querying only works if the query engine can keep up — sub-second responses are the floor, not a stretch goal.
Full-fidelity data
Sampling is invisible until it matters. When AI is asked 'what caused the latency spike on Tuesday?' it needs Tuesday's actual data — not a statistical representation. Sampled logs produce confident-sounding answers to questions that can't really be answered.
Long retention windows
CDN log analysis becomes powerful when you can ask seasonal questions: how does this Black Friday compare to last year? Is this cache-hit degradation a new pattern or a recurrence? 12 months of hot data makes those questions answerable.
Auto-parsing at ingest
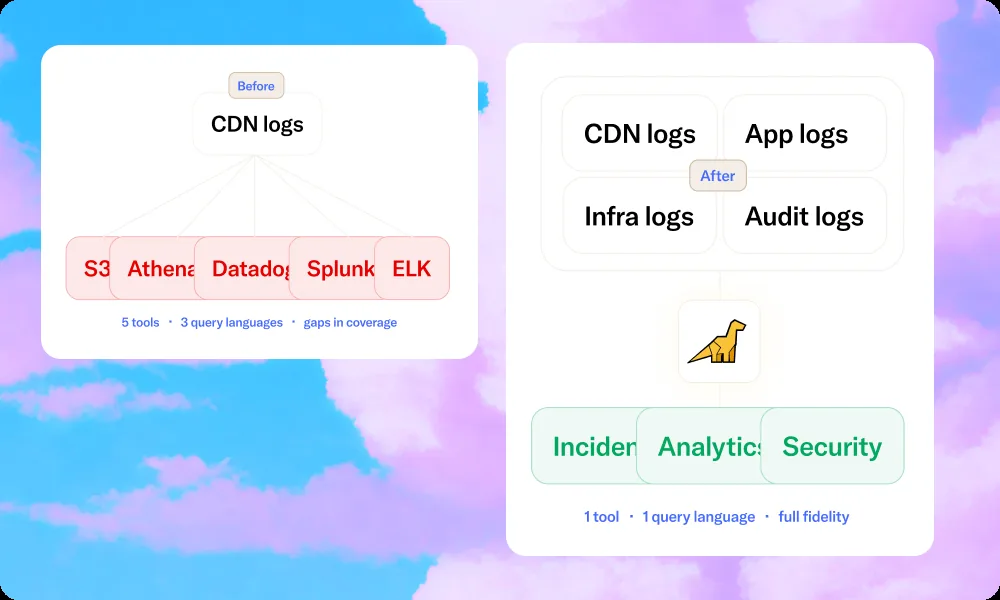
Fastly and Cloudflare use different field names for the same concepts. An AI layer that doesn't understand this generates subtly wrong queries. Bronto auto-parses each provider's format with no config so AI agents can search across datasets.
Autonomous investigation
The most useful AI capability isn't translating one question into SQL — it's autonomously running dozens of relevant queries, synthesizing results, and producing a structured report about what happened and why.
Approach comparison
| Capability | DIY AI Query Layer | Bronto (Purpose-Built) |
|---|---|---|
| Query latency | Depends on underlying DB (often minutes to timeout) | Sub-second across terabytes |
| Natural language queries | Custom-built, schema-specific, breaks when schema changes | Native via MCP Server — maintained, not hand-rolled |
| Dashboard generation | Requires separate build effort | AI Dashboard Builder (plain English) |
| Retention depth | As long as you can afford | 12 months, always hot |
| Full-fidelity data | Depends on your sampling policy | No sampling required |
| Schema maintenance | Your problem — you need to map every CDN provider's format | Zero — auto-parsed on ingest |
| Incident investigation | Manual query + analysis | BrontoScope: autonomous, <10 sec |
| Year-over-year analysis | Possible if data retained | Standard (12-month hot retention) |
| Setup overhead | Weeks to months of engineering | Integrates in hours |
How Bronto solves this
Bronto was built for exactly this workload: designed from the ground up for high-volume, high-retention, low-latency use cases — CDN logs included.
Sub-second search across petabytes
Bronto's bloom filter indexing architecture delivers sub-second search across terabytes of data, with petabyte-scale queries completing in seconds. When your AI agent issues a query, it gets an answer in under a second. Contentstack processes >100TB of CDN logs monthly through Bronto. Typical queries return in 2.2 seconds; queries across 1TB complete in ~25ms.
Native MCP Server integration
Bronto's MCP Server connects your log data directly to AI agents — including Claude Code and other AI-native tools. This means you're not building a custom integration layer or maintaining prompt templates that encode schema knowledge. The connection between your AI tooling and your CDN log data is native, maintained, and doesn't require your team to be the glue.
AI Dashboard Builder
Describe the visualization you want in plain English. Bronto builds it. This removes the query language barrier for operational dashboards — cache hit ratio by region over the last 24 hours, error rates by origin, P99 latency by edge node — without requiring anyone to know Bronto's query syntax or configure panels manually.
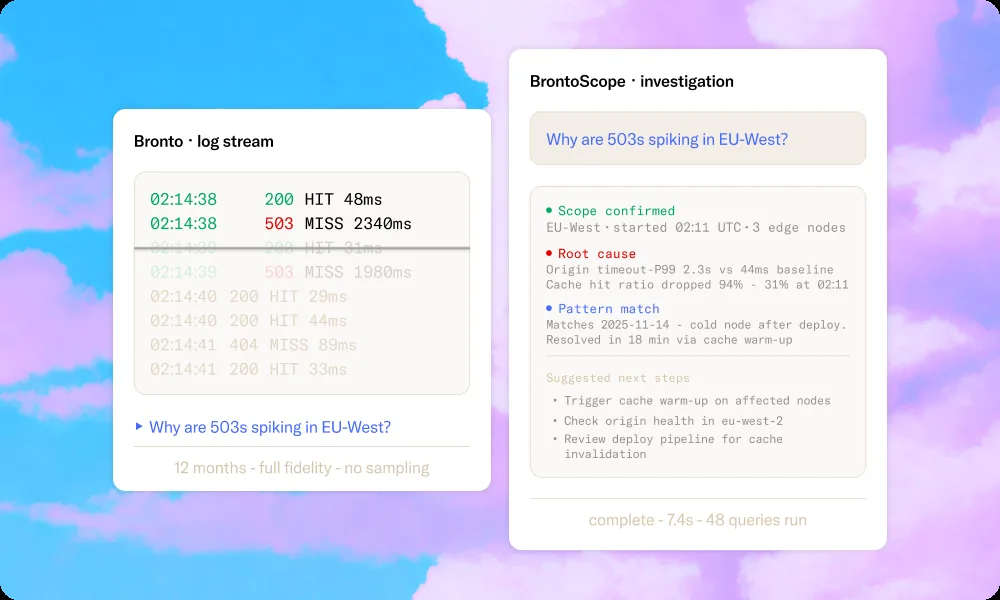
BrontoScope: autonomous incident investigation
When something goes wrong, BrontoScope runs an autonomous investigation against your CDN log data. One click triggers dozens of queries covering scope (affected users, services, regions), possible causes (resource issues, traffic spikes, origin problems), and suggested next steps. The full report generates in under 10 seconds. No prompt engineering required — it's fully autonomous.
12-month hot retention — no rehydration, no tiers
Bronto retains 12 months of log data in hot storage by default. All of it is instantly searchable at the same sub-second performance as your most recent data. This changes what questions AI can actually answer. Year-over-year traffic comparisons, seasonal cache behavior analysis, and long-running security pattern detection are available by default, on day one.
Auto Log Parsing — Fastly, Cloudflare, Akamai out of the box
Bronto automatically parses common CDN log formats on ingest. Fastly, Cloudflare, and Akamai logs are structured and searchable from first ingestion — no regex, no GROK, no schema mapping to maintain. When your AI agent queries CDN logs, it's operating on clean, normalized, consistently structured data.
Start a Free Trial of Bronto
Try Bronto for free for 14 days and see how it handles your logs at any volume, with no query fees and sub-second search.
Start a Free Trial of Bronto →